

امروزه انباره داده(Data Warehouse) بر اساس متدهای جدید از دغدغههای کارشناسان خبره حوزه دیتا میباشد.در این راستا واحد آموزش شرکت هوش تجاری کیسان در مقاله پیشرو به نحوه طراحی انباره داده و لایههای مختلف آن پرداخته است.
لایه های معماری انباره داده
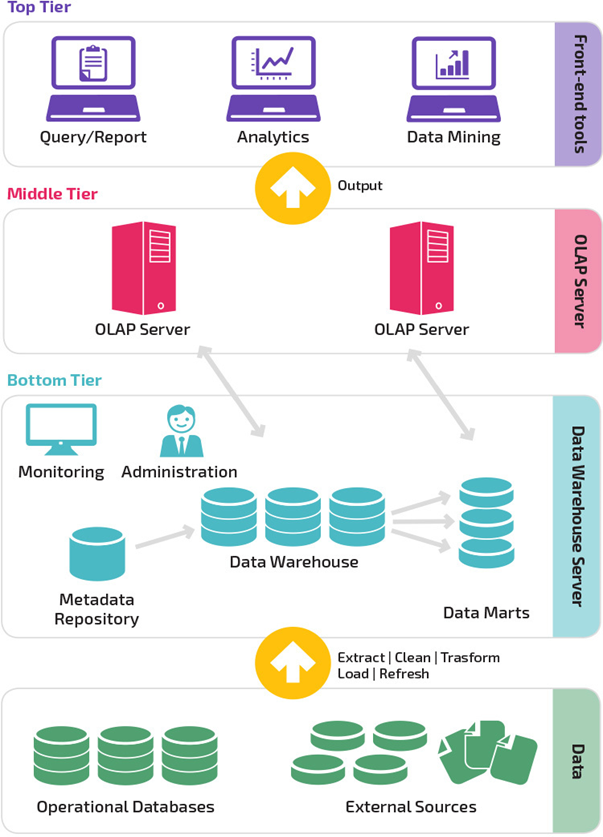
لایه پایینی:
سرور معماری انبار داده، شامل سرور پایگاه داده رابطهای است که از ابزارهای Back-End و دیگر ابزارهای کاربردی برای انتقال اطلاعات از منابع مختلف دادهای مانند پایگاه دادههای تراکنشی و غیره، به لایه پایینی استفاده میشود. این ابزارهای کاربردی و ابزارهای Back-End عملکردهای Extract، Clean ،Load و Refresh را انجام میدهند.
لایه میانی:
لایهی میانی یک سرور OLAP را در اختیار میگیرد که به وسیلهی آن دادهها را به یک ساختار مناسبتر تبدیل میکند تا بتوان به کوئریهای پیچیده بر روی دادهها و تحلیل آنها دسترسی داشت. این سرور به دو روش میتواند کار کند:
الف) Relational OLAP (ROLAP): یک سیستم مدیریت پایگاه داده رابطهای گسترده است. ROLAP عملیات بر روی دادههای چند بعدی را به عملیاتهای رابطهای استاندارد تبدیل میکند.
ب) Multidimensional OLAP (MOLAP): که به طور مستقیم دادههای چند بعدی و عملیات را اجرا می کند.
لایه بالایی:
لایه بالایی، لایه client یا front-end است. این لایه، ابزارهایی را برای استفاده در زمینههای تجزیه و تحلیل داده، پرس وجو (کوئری) گزارشگیری و داده کاوی فراهم میآورد.
نمودار زیر نشان دهنده معماری سه لایهای انباره داده میباشد.
مدلهای انباره داده
از منظر معماریهای انباره داده، ما سه مدل انباره داده داریم:
- انباره داده مجازی
- دیتا مارت
- انباره داده سازمانی
انباره داده مجازی
تعداد کمی از انباره دادههای عملیاتی به عنوان انباره داده مجازی شناخته می شوند. ساخت آن نیازمند به یک ظرفیت مازاد بر روی سرور های پایگاه داده های عملیاتی است.
دیتا مارت
دیتا مارت، شامل یک زیر مجموعه از دادههای سازمان میباشد. این زیر مجموعه از دادهها برای گروههای خاصی از سازمان (یک یا چند واحد سازمانی) ارزشمند است. به عبارت دیگر، ما میتوان ادعا کرد که دیتا مارت حاوی دادههای خاصی برای یک گروه یا واحد خاص از سازمان است. به عنوان مثال، دیتا مارت بازاریابی ممکن است حاوی اطلاعات مربوط به اقلام، مشتریان و فروش باشد. و نهایتا این که دیتا مارتها به موضوعات محدود میشوند.
انباره دادههای سازمانی
یک انباره سازمانی، همهی اطلاعات و موضوعاتی که در کل سازمان وجود دارد را جمعآوری میکند. این نوع انباره داده، دادههای سراسر سازمان را به صورت یکپارچه در اختیار ما قرار میدهد.دادهها از سیستمهای عملیاتی داخلی و تامین کنندگان اطلاعات خارجی، فراهم میآید و نهایتا این که در این نوع انباره دادهها، حجم و گوناگونی اطلاعات می تواند از چند گیگابایت تا چند صد گیگابایت یا چند ترابایت و حتی فراتر باشد.
شِماهای(Schema) ستارهای و گلوله برفی
شمای ستارهای و شمای گلوله برفی دو روش برای ساختار دادن به انباره داده میباشد.
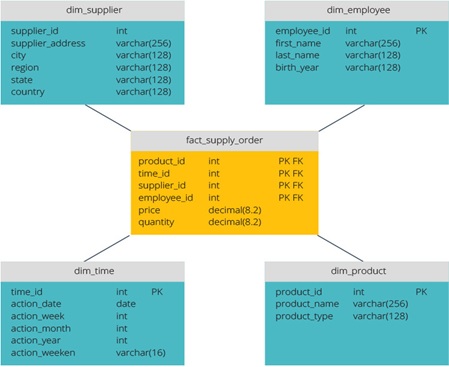
- شمای ستارهای یک مخزن دادهای متمرکز دارد و ذخیرهسازی آن در جدولهای fact table انجام میشود. این شِما، جدول fact table را به یک سری از جداول dimension tables که نرمالسازی نشدهاند، تقسیم میکند. fact table شامل داده های تجمعی است و برای اهداف گزارشدهی مورد استفاده قرار میگیرند، در حالی که dimension tables،دادههای ذخیره شده را توصیف میکند.
- طراحی نرمالسازی نشده، دارای پیچیدگیهای کمتری است، به این دلیل که دادهها به صورت گروهبندی شده هستند. جدول fact table تنها از یک لینک برای پیوستن (Join) به هر جدول dimension table استفاده میکند. طراحی انباره داده با شِمای ستارهای، نوشتن کوئریهای پیچیده را آسانتر میکند. نمایی از این شِما در شکل زیر قابل مشاهده است.
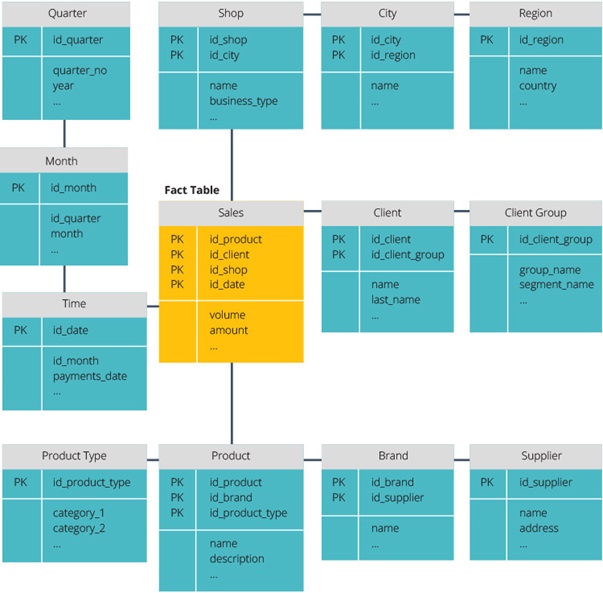
- شِمای گلوله برفی متفاوت است به این دلیل که دادهها به صورت نرمالسازی شده هستند. نرمالسازی به معنای سازماندهی موثر دادهها است تا همه وابستگیهای داده به خوبی تعریف شوند و هر جدول شامل حداقل انحرافات باشد. در این نوع ساختار جداول dimension tables به صورت واحد هستند بنابراین شاخهها درون dimension tables جداگانه قرار میگیرد. شِمای گلوله برفی از فضای دیسک کمتری استفاده میکند و موجب می شود حفظ یکپارچگی داده بهتر صورت بگیرد.عیب اصلی این روش پیچیدگی کوئریها برای دستیابی به دادههاست.(برای به دست آوردن دادهها، معمولا در کوئریها باید از multiple joins استفاده کرد)
-
نمایی از این شِما در شکل زیر قابل مشاهده است.
ETL چیست؟ طراحی انباره داده
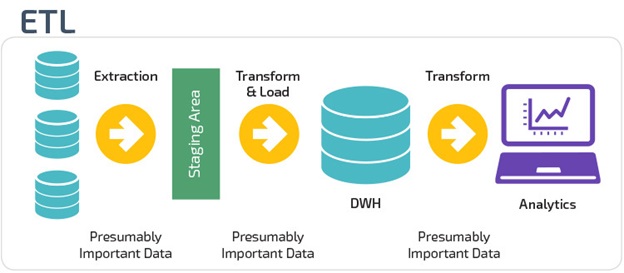
استخراج، تبدیل، بارگزاری (ETL) ، یک فرایند خودکار است که دادههای خام را دریافت میکند، سپس از آنها اطلاعات مورد نیاز برای تجزیه و تحلیل را استخراج مینماید، سپس آنها را به یک فرمت تبدیل میکند که میتواند به نیازهای کسب و کار را تامین کرده و نهایتا آن را به در یک انبارهداده بارگیری کند. ETL عموما دادهها را خلاصه میکند تا اندازه آنها را کاهش دهد و همچنین عملکرد را برای نوع خاصی از تجزیه و تحلیلها بهبود میبخشد. طراحی انباره داده
چرا ETL مهم است؟ طراحی انباره داده
- هنگامی که با انبار دادههای سازمانی (اطلاعات در حالت استراحت) استفاده میشود ETL زمینههای تاریخی عمیقی برای کسب و کار فراهم میآورد.
- با ارائه یک نمایه تلفیقی، ETL باعث میشود که تجزیه و تحلیل و گزارش دادهها و ابتکارات در ارتباط با آنها، برای کاربران کسب و کار آسانتر شود.
- ETL میتواند بهرهوری حرفهای دادهها را بهبود ببخشد؛ زیرا این پروتکلها رمزهای پردازش شده را مجددا مورد استفاده قرار میدهد که این امر باعث میشود دادهها را بدون نیاز به مهارتهای فنی برای نوشتن کد یا اسکریپت انتقال داد.
- ETL در طول زمان تکامل یافته است تا از نیازهایی که در ارتباط با یکپارچگی برای مواردی مانند جریان دادهای بروز میکنند، پشتیبانی کند.
- سازمانها به ETL نیاز دارند تا دادهها را با هم تجمیع کنند، از دقت دادهها اطمینان حاصل کنند و حسابرسی مورد نیاز برای انباره دادهها، گزارشدهی و تجزیه و تحلیل را فراهم آورند. طراحی انباره داده
ETL چگونه کار می کند؟
ETL درارتباط نزدیکی با برخی مفاهیم دیگری از قبیل توابع، فرآیندها و تکنیکهای یکپارچهسازی اطلاعات است. درک این مفاهیم، دیدگاه واضحتری از نحوه عملکرد ETL فراهم میکند. طراحی انباره داده
ساخت ETL با پردازش دستهای طراحی انباره داده
از طریق پردازش زیر شما میتوانید یک ETL ایجاد نماید.در این مدل از ETL پردازش و انتقال به صورت دستهای از منابع پایگاه داده به منابع انباره داده صورت میگیرد.برای ساخت ETL با روش پردازش دستهای به صورت زیر عمل میکنیم:
-
دادههای مرجع
مجموعهای از دادهها را ایجاد کنید که مجموعهای از مقادیر مجاز را تعریف میکند و ممکن است دادههای شما را نیز در بر بگیرد.
-
استخراج از منابع دادهای
پایهی موفقیت در مراحل بعدی ETL، استخراج دادهها به صورت درست است. بیشتر سیستمهای ETL ترکیبی از دادهها از منابع دادهای مختلف هستند، که هر کدام از منابع، سازماندهی دادهای و فرمت خود را دارند.(که شامل پایگاه دادهای رابطهای، پایگاه دادههای غیر رابطهای،XML ، JSON ، CSV، فایلها و .. میباشند) استخراج موفق ، دادهها را به یک فرمت واحد تبدیل میکند تا پردازش استاندارد باشد. طراحی انباره داده
-
اعتبارسنجی دادهها
اعتبار سنجی دادهها یک فرایند خودکار است که تایید میکند که آیا دادههای بدست آمده و استخراج شده شده از منابع دادهای مختلف دارای مقادیر مورد انتظار هستت یا نه. – برای مثال، در پایگاه داده معاملات مالی از سال گذشته، فیلد تاریخ باید حاوی تاریخ معتبر در طی 12 ماه گذشته باشد. اگر دادهها قوانین اعتبارسنجی را رعایت نکنند، موتور اعتبار سنجی داده ها را نمیپذیرد.
-
تبدیل دادهها
حذف اطلاعات اضافی و غیر اصلی یا حذف اطلاعات نادرست (تمیز کردن)، اعمال قوانین کسب و کار، بررسی یکپارچگی دادهها (اطمینان حاصل شود که دادهها در منبع دادهای خراب نبوده یا توسط ETL خراب نشدهاند و اطلاعات در مراحل قبلی حذف نشدهاند) طراحی انباره داده
-
مرحلهی نمایش دادهها در پایگاه داده
شما به طور معمول دادههای تبدیل شده را مستقیما در انبار دادههای هدف قرار نمیدهید. ابتدا دادهها باید به یک پایگاه اطلاعاتی متصل شوند و در معرض نمایش قرار بگیرد تا اگر چیزی اشتباه باشد، roll back راحتر باشد.
-
انتشار دادهها در انبار داده
دادهها را در جداول هدف بارگذاری کنید. برخی از انباره دادهها هر زمان که ETL یک دسته جدید را بارگذاری میکند، اطلاعات موجود را بازنویسی میکند.این ممکن است روزانه، هفتگی یا ماهانه رخ دهد. در موارد دیگر، ETL میتواند دادههای جدید را بدون تغییر مجدد اضافه کند، که این کار با نشانهگذاری بر روی آنها صورت میگیرد. شما باید این کار را با دقت انجام دهید تا از انفجار انباره دادهها به علت کمبود فضای دیسک و محدودیتهای عملکرد جلوگیری شود. طراحی انباره داده
ساخت ETL با پردازش جریان دادهای طراحی انباره داده
اغلب پردازش دادهای مدرن، شامل دادههای بلادرنگ نیز میشوند. به عنوان مثال تحلیل دادهی وب از یک وبسایت تجارت الکترونیک بزرگ.در این شرایط نمیتوان تبدیل و استخراج دادهها را در یک دسته بزرگ، انجام داد.پس این نیاز بوجود میآید که ETL در جریان دادهها صورت بگیرد. این امر به این معنی است که Client applicationها که دادهها را به منابع دادهای ارسال میکنند، باید دادهها را بلافاصله به پایگاه دادههای هدف منتقل و ذخیره کنند.
امروزه ابزارهای پردازش جریان دادهای زیادی در دسترس هستند که برخی از آنها در زیر آمده است:
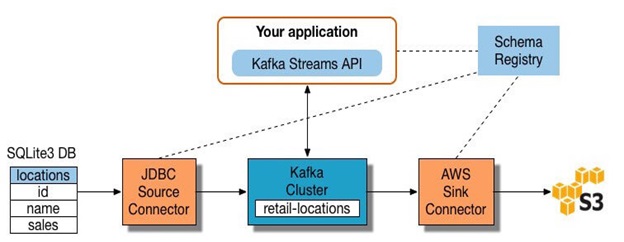
Apache Samza, Apache Storm, and Apache Kafka .
شکل زیر نشان دهنده ی ETL بر مبنای Kafka است.





بدون دیدگاه