

در پایگاهدادهها و زبان SQL، یکی از دستورات پرکاربرد برای فیلتر کردن نتایج تکراری، DISTINCT است. این دستور ساده اما قدرتمند به برنامهنویسان و تحلیلگران داده کمک میکند تا از میان دادههای انبوه، اطلاعات یکتا و منحصربهفرد استخراج کنند. در این مقاله بهطور جامع بررسی میکنیم که DISTINCT در SQL چیست، چه کاربردهایی دارد و چه زمانی استفاده از آن ضروری میشود. همچنین مثالهای عملی و نکات بهینهسازی را توضیح خواهیم داد.
DISTINCT در SQL چیست؟
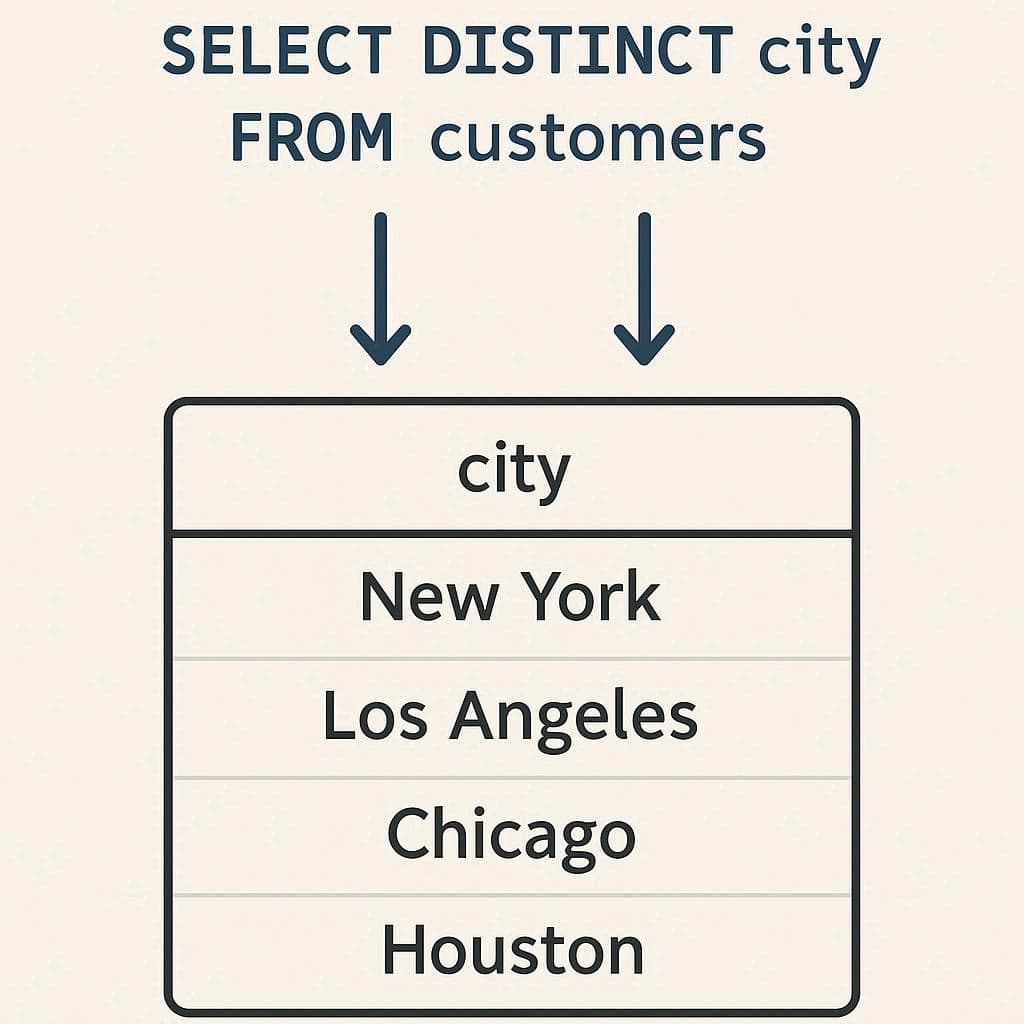
زمانی که دادهها از یک جدول پایگاهداده استخراج میشوند، احتمال دارد رکوردهای تکراری در نتیجه نمایش داده شوند. دستور DISTINCT در SQL به ما اجازه میدهد تا این دادههای تکراری حذف شوند و تنها مقادیر یکتا نمایش داده شوند.
بهعنوان مثال:
این کوئری تنها نام شهرهای منحصربهفرد مشتریان را برمیگرداند و اگر چند مشتری از یک شهر باشند، آن شهر فقط یکبار در خروجی نمایش داده میشود.
چه زمانی DISTINCT ضروری است؟
اگرچه همیشه نیاز به استفاده از DISTINCT نداریم، اما در شرایط زیر استفاده از آن ضروری خواهد بود:
-
حذف دادههای تکراری از گزارشها: زمانی که میخواهیم گزارشی دقیق و بدون تکرار ارائه دهیم.
-
تحلیل آماری روی دادههای یکتا: مثلاً محاسبه تعداد شهرهای مختلف یا تعداد محصولات خاص.
-
ساخت لیستهای منحصربهفرد: مانند لیست مشتریان منحصربهفرد یا دستهبندی کالاها.
-
تضمین کیفیت دادهها: در بسیاری از مواقع دادهها به دلیل خطاهای ورودی یا ثبت چندباره رکوردها تکراری هستند. DISTINCT کمک میکند تا این مشکل مدیریت شود.
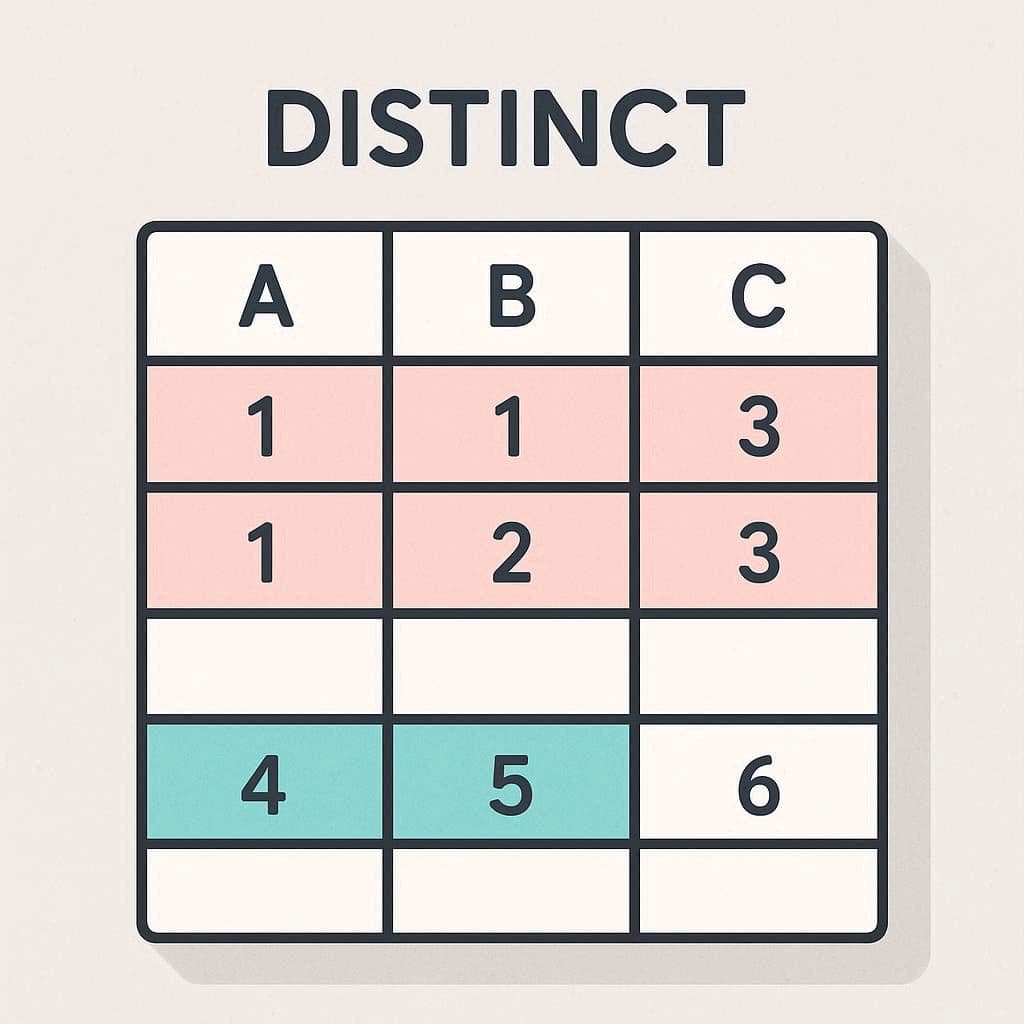
مثالهای عملی DISTINCT در SQL
1. استفاده ساده برای ستون تکی
این دستور لیستی از دپارتمانهای یکتا را نمایش میدهد.
2. استفاده برای چند ستون
اینجا ترکیب دو ستون بررسی میشود. یعنی فقط مقادیر منحصربهفرد ترکیب دپارتمان و عنوان شغلی نمایش داده میشوند.
3. ترکیب با COUNT برای شمارش یکتاها
این کوئری تعداد شهرهای منحصربهفرد مشتریان را نمایش میدهد.
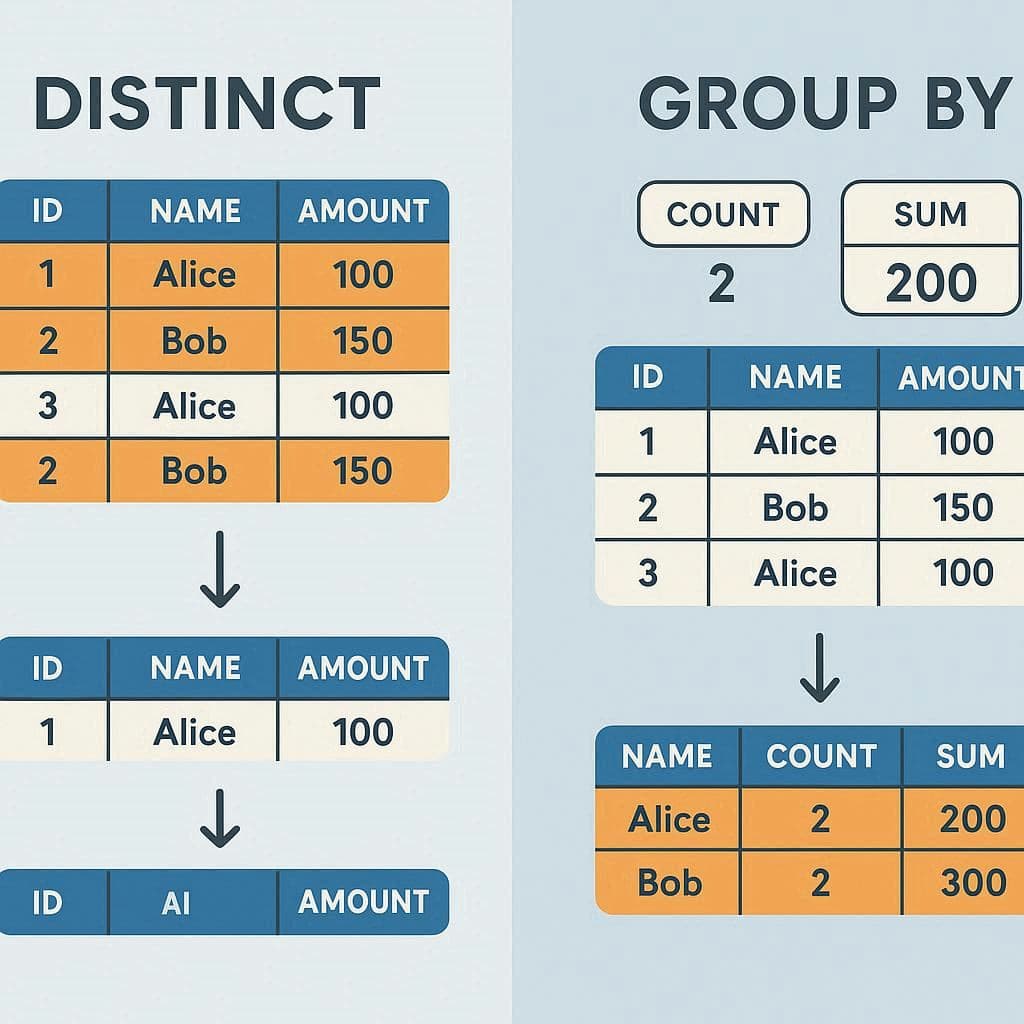
تفاوت DISTINCT و GROUP BY
گاهی اوقات کاربران SQL بین DISTINCT و GROUP BY دچار سردرگمی میشوند.
-
DISTINCT تنها برای حذف مقادیر تکراری و نمایش یکتاها به کار میرود.
-
GROUP BY دادهها را بر اساس ستونهای مشخص دستهبندی میکند و معمولاً همراه با توابع تجمعی (COUNT, SUM, AVG) استفاده میشود.
مثال:
شهرهای یکتا را نمایش میدهد.
تعداد مشتریان در هر شهر را نمایش میدهد.
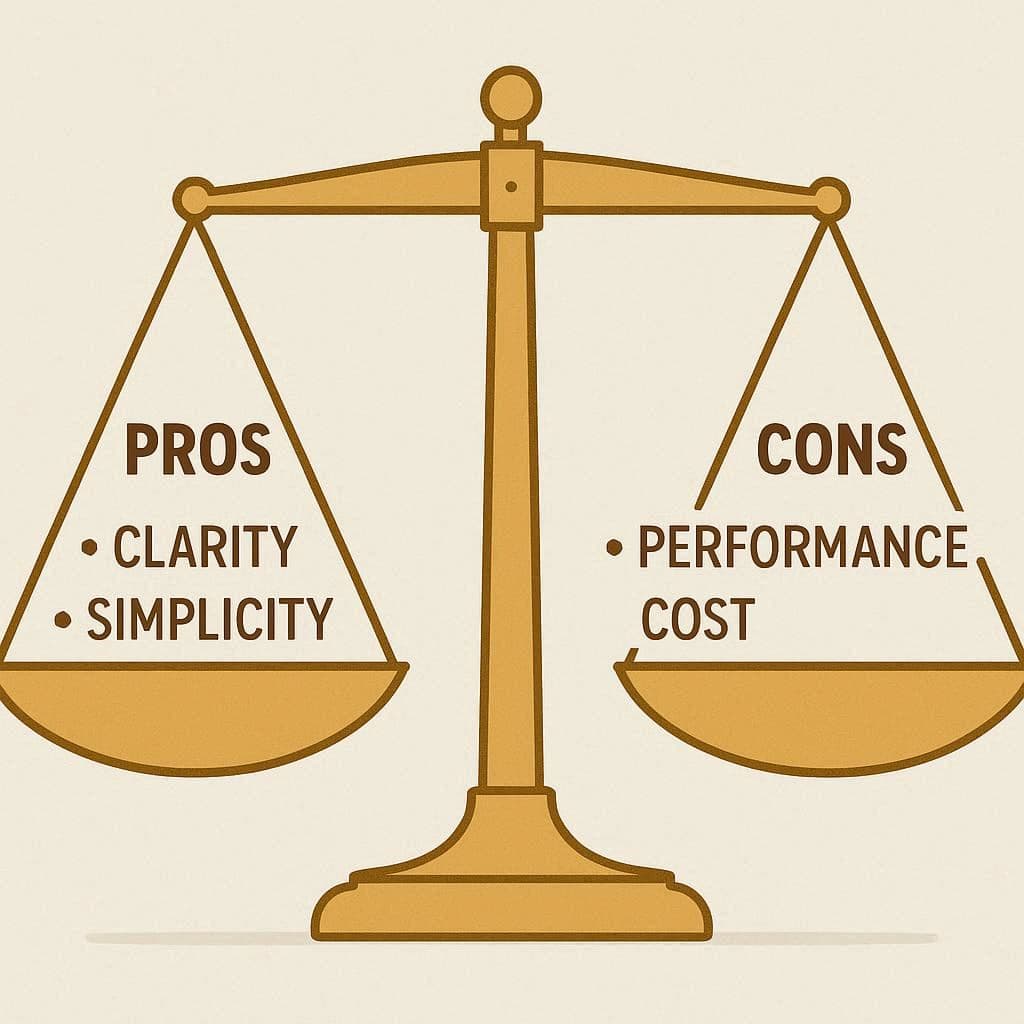
مزایا و معایب استفاده از DISTINCT
✅ مزایا
-
سادگی در حذف دادههای تکراری
-
مناسب برای گزارشگیری سریع
-
ترکیبپذیری با توابع دیگر مثل COUNT
❌ معایب
-
مصرف بالای منابع در جداول بزرگ
-
کاهش سرعت اجرای کوئری در دادههای حجیم
-
گاهی جایگزینهای بهینهتر مثل GROUP BY یا ROW_NUMBER() وجود دارند
نکات بهینهسازی هنگام استفاده از DISTINCT
-
ایجاد ایندکس روی ستونها: اگر ستون مورد استفاده در DISTINCT ایندکس داشته باشد، اجرای کوئری سریعتر خواهد شد.
-
انتخاب تعداد ستون کمتر: هرچه ستونهای بیشتری در DISTINCT استفاده شوند، هزینه پردازش بالاتر میرود.
-
بررسی نیاز واقعی: همیشه قبل از استفاده، باید بررسی کرد که آیا DISTINCT ضروری است یا میتوان از راهکارهای دیگر مثل GROUP BY یا JOIN استفاده کرد.
-
استفاده از توابع پنجرهای: در موارد پیچیده، توابعی مثل ROW_NUMBER() یا RANK() جایگزین بهینهتری برای حذف رکوردهای تکراری هستند.
سناریوهای واقعی استفاده از DISTINCT
🎯 تحلیل فروش
فرض کنید جدولی از سفارشها داریم و میخواهیم بدانیم در چند کشور مختلف سفارش ثبت شده است:
🎯 مدیریت کاربران
برای ارسال ایمیل تبلیغاتی، میخواهیم هر کاربر فقط یکبار ایمیل دریافت کند:
🎯 پایگاه داده آموزشی
لیست یکتای دروس ارائهشده در دانشگاه:
جایگزینهای DISTINCT در شرایط خاص
در برخی موارد، میتوان بهجای DISTINCT از روشهای دیگر استفاده کرد:
-
GROUP BY برای گروهبندی و تجمیع دادهها
-
ROW_NUMBER() برای حذف رکوردهای تکراری و نگهداشتن رکورد اصلی
-
EXISTS برای بررسی وجود دادههای یکتا در کوئریهای پیچیده
جمعبندی
دستور DISTINCT در SQL یکی از ابزارهای مهم برای استخراج دادههای یکتا و حذف رکوردهای تکراری است. استفاده درست از این دستور به بهبود کیفیت گزارشها و دقت تحلیل دادهها کمک میکند. اما باید در نظر داشت که در جداول بسیار بزرگ ممکن است کارایی سیستم را کاهش دهد. بنابراین، آگاهی از شرایط ضروری استفاده از DISTINCT و شناخت جایگزینهای آن مثل GROUP BY یا توابع پنجرهای، کلید طراحی کوئریهای بهینه است.
اگر شما یک تحلیلگر داده یا برنامهنویس SQL هستید، بهتر است همیشه قبل از استفاده از DISTINCT به این سوال پاسخ دهید:
آیا واقعاً به دادههای یکتا نیاز دارم یا میتوانم با ابزار دیگری همان نتیجه را بهدست آورم؟





بدون دیدگاه